Intended Audience
- Science/Research
License
- OSI Approved :: MIT License
Programming Language
- Python :: 3
- Python :: 3.10
- Python :: 3.11
- Python :: 3.12
- Python :: 3.13
Topic
- Scientific/Engineering :: Artificial Intelligence
CJE — Causal Judge Evaluation
LLM-judge scores are cheap and plentiful, but their scale can differ materially from the oracle outcome you care about. In the paper's Chatbot Arena benchmark, naive 95% intervals around raw judge-score means had 0% coverage. CJE calibrates a judge against sampled oracle labels, evaluates policies on fresh responses, and reports uncertainty and diagnostics under explicit sampling and transport assumptions.
![]()
![]()
![]()
60 seconds
pip install cje-eval
Generate one response from each candidate policy on a shared prompt set, judge every response, and attach ground-truth labels (oracle_label) to a probability sample you can afford: human ratings, expert review, or a downstream KPI. Any bounded judge and oracle scales work (0–1, 0–100, Likert). This minimal example has 20 shared prompts and 10 labels, all sampled from one policy:
from cje import analyze_dataset
# One policy carries the calibration slice. This is enough to fit a shared
# judge-to-oracle map, but residual transport to fable-5 must be audited with
# separate held-out oracle probes before making transport-dependent claims.
labeled = [(0.62, 0.55), (0.68, 0.60), (0.72, 0.70), (0.76, 0.74), (0.79, 0.75),
(0.83, 0.80), (0.85, 0.90), (0.88, 0.92), (0.91, 0.88), (0.95, 0.97)]
unlabeled = [0.64, 0.69, 0.73, 0.77, 0.80, 0.84, 0.87, 0.89, 0.92, 0.94]
judge_only = [0.70, 0.74, 0.75, 0.78, 0.81, 0.83, 0.86, 0.90, 0.93, 0.94,
0.72, 0.76, 0.79, 0.80, 0.84, 0.85, 0.88, 0.89, 0.91, 0.95]
draws = {
"gpt-5.6": [
{"prompt_id": f"q{i:02d}", "judge_score": s, "oracle_label": y}
for i, (s, y) in enumerate(labeled + [(u, None) for u in unlabeled])
],
"fable-5": [
{"prompt_id": f"q{i:02d}", "judge_score": s}
for i, s in enumerate(judge_only)
],
}
results = analyze_dataset(fresh_draws_data=draws)
for policy, estimate, (lo, hi) in zip(
results.metadata["target_policies"], results.estimates, results.ci()
):
print(f"{policy:15s} {estimate:.3f} 95% CI [{lo:.3f}, {hi:.3f}]")
The call returns a point estimate for every policy, including policies with no calibration labels of their own. Supported inference paths account for evaluation sampling and finite-label calibration uncertainty; interpretation still depends on the declared sampling design and shared-calibration assumptions. CJE automatically reports a scalar score-support badge for each policy. That badge checks whether target judge scores extrapolate beyond the labeled score range; it does not test mean residual bias, covariate shift, or ranking validity.
Residual transport is a separate, opt-in equivalence audit on oracle probes that were not used to fit the calibrator. Supply probes with the analysis when you want their states wired into result diagnostics and reliability gates:
from cje import TransportAuditConfig
transport = TransportAuditConfig(
probes_by_policy={"fable-5": held_out_probe_rows},
delta_max_by_policy={"fable-5": 0.03}, # OUTPUT units (units of results.estimates)
)
results = analyze_dataset(fresh_draws_data=draws, transport=transport)
print(results.metadata["transport_audits"]["fable-5"]["status"])
Policies without supplied probes are explicitly NOT_CHECKED. For an already fitted calibrator, the array-first primitive runs the same audit directly:
from cje import transport_audit
audit = transport_audit(
probe_scores,
probe_labels,
results.calibrator,
delta_max=0.03, # predeclared practical bias margin, probe oracle-label units
cluster_ids=prompt_ids, # independent sampling clusters
family_size=2, # policies/groups audited for this decision
)
print(audit.summary())
PASS requires the simultaneous residual CI to lie wholly inside [-delta_max, +delta_max]; FAIL requires it to be wholly outside. An overlapping interval is INCONCLUSIVE, and omitting the margin is NOT_GRADED. Fewer than 20 effective clusters withholds PASS (INCONCLUSIVE) — but a CI wholly outside the margin still grades FAIL, so an under-sized probe cannot defeat the hard gate. Only an observed FAIL adds a hard reliability gate; every other unresolved state remains visible as a limitation without suppressing the estimate.
When a policy's judge scores land mostly outside the labeled scalar range, CJE attaches REFUSE-LEVEL to the estimate:
REFUSE-LEVEL for policy 'candidate': 88.3% of fresh-draw judge scores fall
outside the oracle calibration range [0.161, 0.595]. Do not report level
(absolute) claims for this policy from this fit. Collect oracle labels covering
the missing score range.
Diagnostics never act silently: results.best_policy() demotes a gate-flagged argmax to the best gate-passing policy (the default, reliable_only=True), and the demotion is loud — the flagged raw winner stays visible with its limitations, and the divergence is spelled out (reliable_only=False returns the raw argmax, marked flagged):
Best by point estimate: candidate
Limitations: flagged by the reliability gates; residual transport NOT_CHECKED
Best reliable policy: baseline — raw argmax candidate was flagged (boundary:
88.3% of judge scores outside the oracle calibration range); pass
reliable_only=False for the raw argmax
→ Runnable Colab with real data · Full docs
Is CJE the right tool?
| Your situation | Use |
|---|---|
| Rank/compare policies using an LLM judge, with some ground-truth labels | CJE |
| One dataset, labels sampled from it, want a CI on its mean | PPI works; CJE's calibrated_mean_ci provides the same core primitive plus scalar-support metadata and an optional held-out residual audit |
| Evaluate many policies without labeling under each | CJE, provided the shared calibration and sampling assumptions are justified; use held-out probes and an explicit bias margin to grade residual transport |
| Predict how a specific response will score | Not CJE — per-item prediction (conformal methods) |
| Off-policy estimates from logs only (importance weighting / doubly robust) | pip install "cje-eval==0.3.*" — the frozen OPE line; this library is Direct-mode only (see Why Direct mode only?) |
How it works
- Calibrate: learn the judge → oracle mapping on the labeled slice (isotonic, two-stage when needed; mean-preserving by construction; cross-fitted).
- Evaluate: score every policy's fresh responses through the calibrated judge and compare policies on the same prompts.
- Diagnose: automatically report scalar score-range support, and optionally run a held-out residual equivalence audit with a predeclared practical margin. These answer different questions and are reported separately.
Confidence intervals include finite-label calibration uncertainty on supported inference paths. Their interpretation still depends on the oracle sampling design, shared-calibration assumptions, and any transport claims being made.
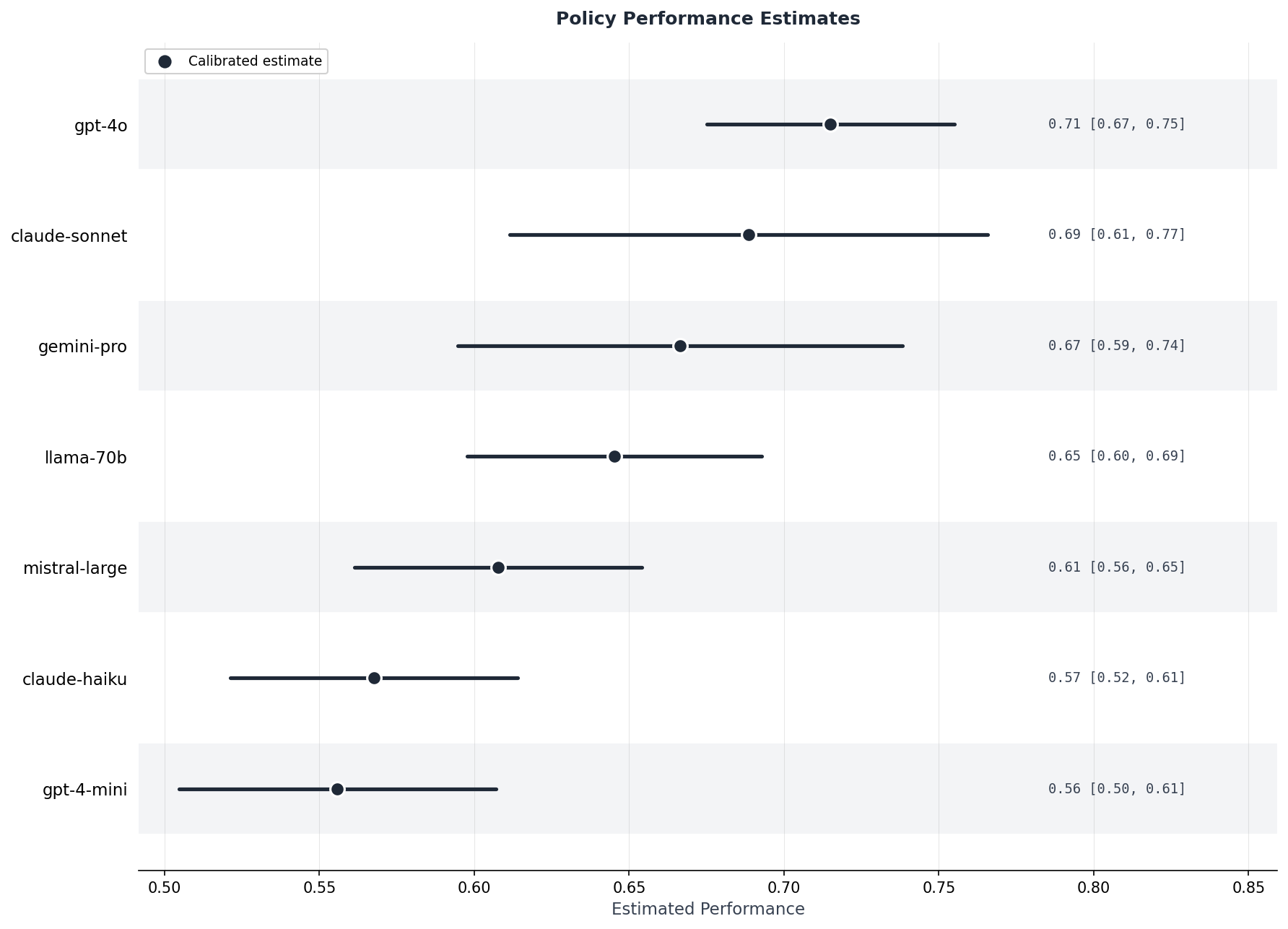
Calibrated estimates with 95% CIs under the experiment's stated sampling and calibration assumptions
Validation on real ground truth
- HealthBench (physician labels, n=29,511): two LLM judges were overconfident by 24.5 and 13.0 points and disagreed with each other by up to 73 points on specific criteria categories. Calibrated on 5% physician labels (~1,400 records), both converged to the physician ground truth. Read the full audit →
- Chatbot Arena (4,961 prompts, 5 policies): 99% pairwise ranking accuracy at a 5% oracle fraction — 14× cheaper than labeling everything, with ~95% CI coverage vs 0% for naive judge-score CIs. An adversarial policy that fools the judge is correctly flagged by the transport audit. Paper →
The array API
calibrated_mean_ci is the library's bottom layer: a ppi_py-style primitive that takes plain NumPy arrays and returns a calibrated mean and interval. Use it when you have one sample of judge scores and a probability-sampled oracle slice; use analyze_dataset for multi-policy comparisons.
import numpy as np
from cje import calibrated_mean_ci
rng = np.random.default_rng(0)
scores = rng.uniform(size=400) # judge scores for every sample
labels = np.full(400, np.nan) # NaN = unlabeled
labeled = rng.choice(400, size=100, replace=False) # oracle slice (25%)
labels[labeled] = np.clip(scores[labeled] + rng.normal(0, 0.1, size=100), 0, 1)
result = calibrated_mean_ci(scores, labels)
print(result.summary())
Calibrated mean: 0.5316 (SE 0.0183, CI [0.4951, 0.5678], n=400, n_oracle=100, bootstrap)
When partial oracle coverage requires calibration, result.calibrator predicts in the same public judge and oracle units supplied by the caller. Complete oracle coverage returns the direct oracle mean with result.calibrator is None. Grade any fitted calibrator's reuse on an independent probe with transport_audit(..., delta_max=<practical margin>); without a margin the result is NOT_GRADED. result.diagnostics["boundary_card"] carries the separate scalar score-support badge when calibration is fitted.
Documentation
| Resource | Description |
|---|---|
| Interactive Tutorial | Walk through a complete example in Colab — no setup required |
| CJE in 3 Minutes | Video: why raw judge scores mislead and how CJE fixes it |
| Technical Walkthrough | Video: calibration, evaluation, and transport auditing pipeline |
| Operational Playbook | End-to-end runbook: audits, drift correction, label budgeting |
| MIGRATING-0.6.md | Upgrading from an earlier release? See MIGRATING-0.6.md |
| Planning Notebook | Optimize your evaluation budget with pilot data |
| Full Docs | Installation, assumptions, API reference, research notes |
Bridges: Already running evals in Promptfoo, TruLens, LangSmith, or OpenCompass? Convert those outputs into CJE format with one command.
Module deep dives: Calibration · Diagnostics · Estimators · Interface/API · Data formats
Use CJE from your AI agent
skills/cje/ is an Agent Skill that teaches Claude Code and similar agents to run CJE correctly — reshape your data, drive the labeling loop, calibrate, compare, and respect the refusal gates — instead of averaging raw judge scores.
- Claude Code (all projects):
mkdir -p ~/.claude/skills/cje && curl -fsSL https://raw.githubusercontent.com/cimo-labs/cje/main/skills/cje/SKILL.md -o ~/.claude/skills/cje/SKILL.md && curl -fsSL https://raw.githubusercontent.com/cimo-labs/cje/main/skills/cje/reference.md -o ~/.claude/skills/cje/reference.md - Project-level:
cp -r skills/cje .claude/skills/from a checkout of this repo. - Other agents: point your agent at
skills/cje/SKILL.md— plain Markdown;reference.mdloads on demand.
Why Direct mode only (no IPS/DR)?
CJE is Direct-mode only: fresh draws, calibrated judge, audits. There is no off-policy machinery — no importance-sampling or doubly-robust estimators (calibrated-ips, dr-cpo, mrdr, tmle, stacked-dr), teacher forcing, SIMCal weight stabilization, or overlap diagnostics. Our own paper's results drove that design: for realistic LLM policy pairs, importance weighting failed even when ESS looked healthy (target-typicality coverage 0.19–0.49, far below the 0.70 gate), and the best DR stack merely matched Direct mode's accuracy at ~12× the compute. Direct mode is what the evidence supports, so it is the whole product.
- Need IPS/DR from logged propensities? Pin the frozen OPE line:
pip install "cje-eval==0.3.*"(maintained on the0.3.xbranch; docs at thev0.3.0tag; requires Python <=3.12 — on 3.13 use a 3.12 env for OPE). - Have old logged data with
judge_score+oracle_label? It works as the calibration source:analyze_dataset(fresh_draws_dir=..., calibration_data_path="logged.jsonl"). - OPE entry points raise migration errors that say exactly this.
Full version history in the CHANGELOG.
Development
git clone https://github.com/cimo-labs/cje.git
cd cje && poetry install && make test
Citation
If you use CJE in your research, please cite:
@misc{landesberg2025causaljudgeevaluationcalibrated,
title={Causal Judge Evaluation: Calibrated Surrogate Metrics for LLM Systems},
author={Eddie Landesberg},
year={2025},
eprint={2512.11150},
archivePrefix={arXiv},
primaryClass={stat.ME},
url={https://arxiv.org/abs/2512.11150},
}
License
MIT — See LICENSE for details.