TokenSpeed-MLA
Speed-of-light TokenSpeed MLA kernels for Blackwell (SM100/SM103) with:
MLA prefill:- CuTe DSL JIT backend for ragged varlen FMHA (no padding)
- Optional AOT binary backend (pre-compiled
.so) for FP8 E4M3 prefill - BF16 output, optional LSE output, causal/non-causal modes, PDL support
MLA decode:- CuTe DSL decode kernels for FP16/BF16/FP8 input paths
- FP8 decode writes BF16 output for better downstream stability
- Split-KV + workspace path with runtime auto-sizing and compile caching
MLA K/V pack + FP8 quantize:- Fused Triton kernel replacing
cat + cast + castin chunked prefill - Supports strided views and optional pre-allocated output buffers
- Fused Triton kernel replacing
This package includes performance-oriented optimizations for latency-sensitive
serving workloads, especially coding agent style use cases with high request
concurrency, short decode steps, and strict time-to-first-token/next-token
requirements. For MLA prefill kernel, we supported two version, one is the open
source version, and another is the binary version with some Nvidia internal knobs
for better performance. For MLA decode kernel, small q_len * num_heads
configurations can fold a query-token group (fold_sq_factor) into heads for
better tile utilization; remaining query groups are scheduled across the query
sequence dimension.
Performance Numbers
Prefill Performance
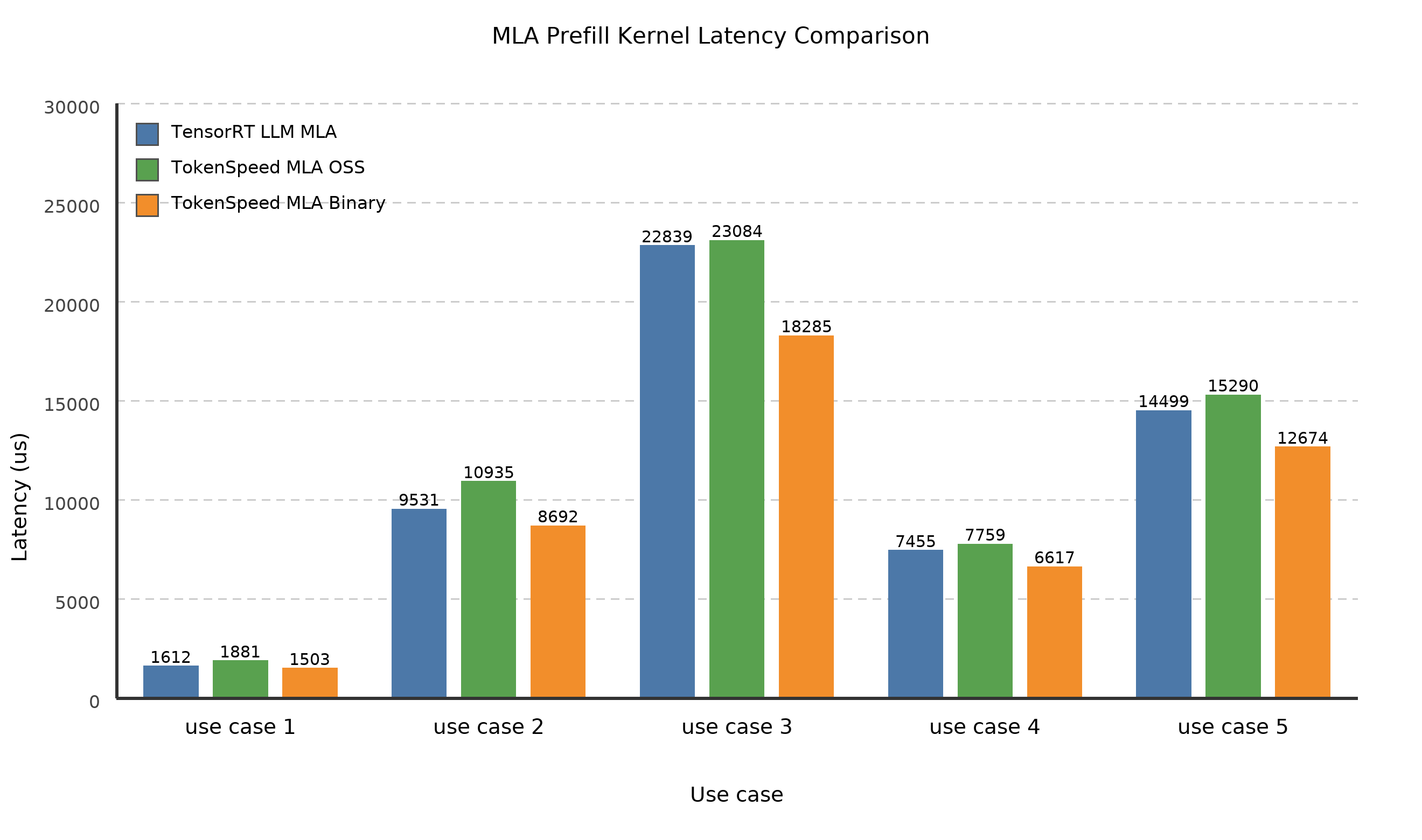
Where:
use case 1: batch_size = 1, seqlen_qo = 8 * 1024, seqlen_kv = 8 * 1024
use case 2: batch_size = 1, seqlen_qo = 8 * 1024, seqlen_kv = 32 * 1024
use case 3: batch_size = 1, seqlen_qo = 8 * 1024, seqlen_kv = 64 * 1024
use case 4: batch_size = 4, seqlen_qo = 512, seqlen_kv = 80 * 1024
use case 5: batch_size = 4, seqlen_qo = 1024, seqlen_kv = 80 * 1024
TensorRT-LLM’s MLA performance is already strong. The TokenSpeed MLA Prefill kernel offers two backends: the open-source version and a binary version with superior performance. While the open-source version is slightly slower than TensorRT-LLM’s native implementation, the AOT binary version excels across tested use cases. Its key optimization is a fine-tuned softmax implementation leveraging NVIDIA-internal knobs.
The performance numbers can be collected using the following command line:
python ./tokenspeed-mla/python/tokenspeed_mla/fmha.py \
--is_causal \
--bottom_right_align \
--in_dtype Float8E4M3FN \
--out_dtype Float8E4M3FN \
--q_shape 1,8192,128,192 \
--k_shape 1,8192,128,192 \
--warmup_iterations 10 \
--iterations 10 \
--skip_ref_check
Decode Performance
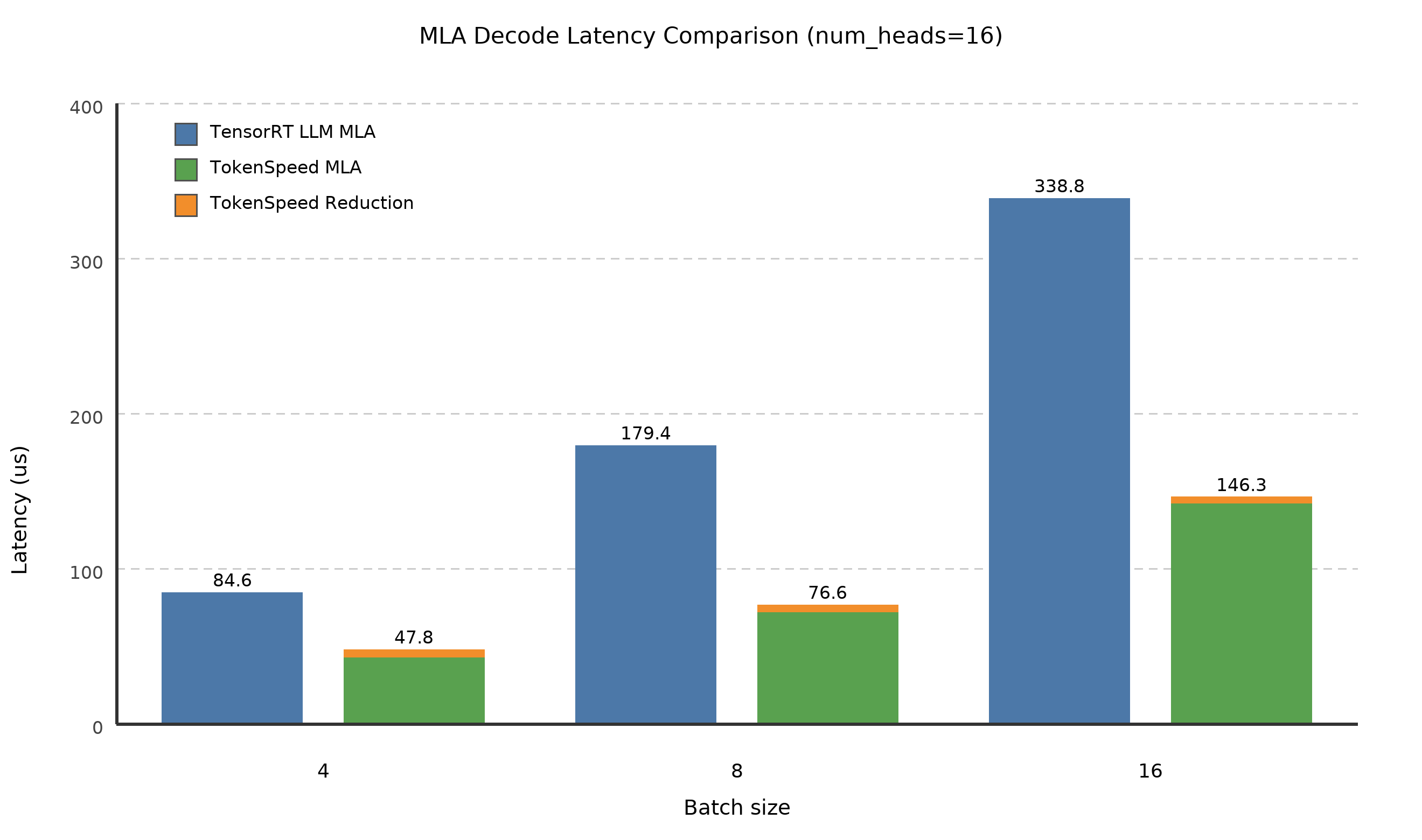
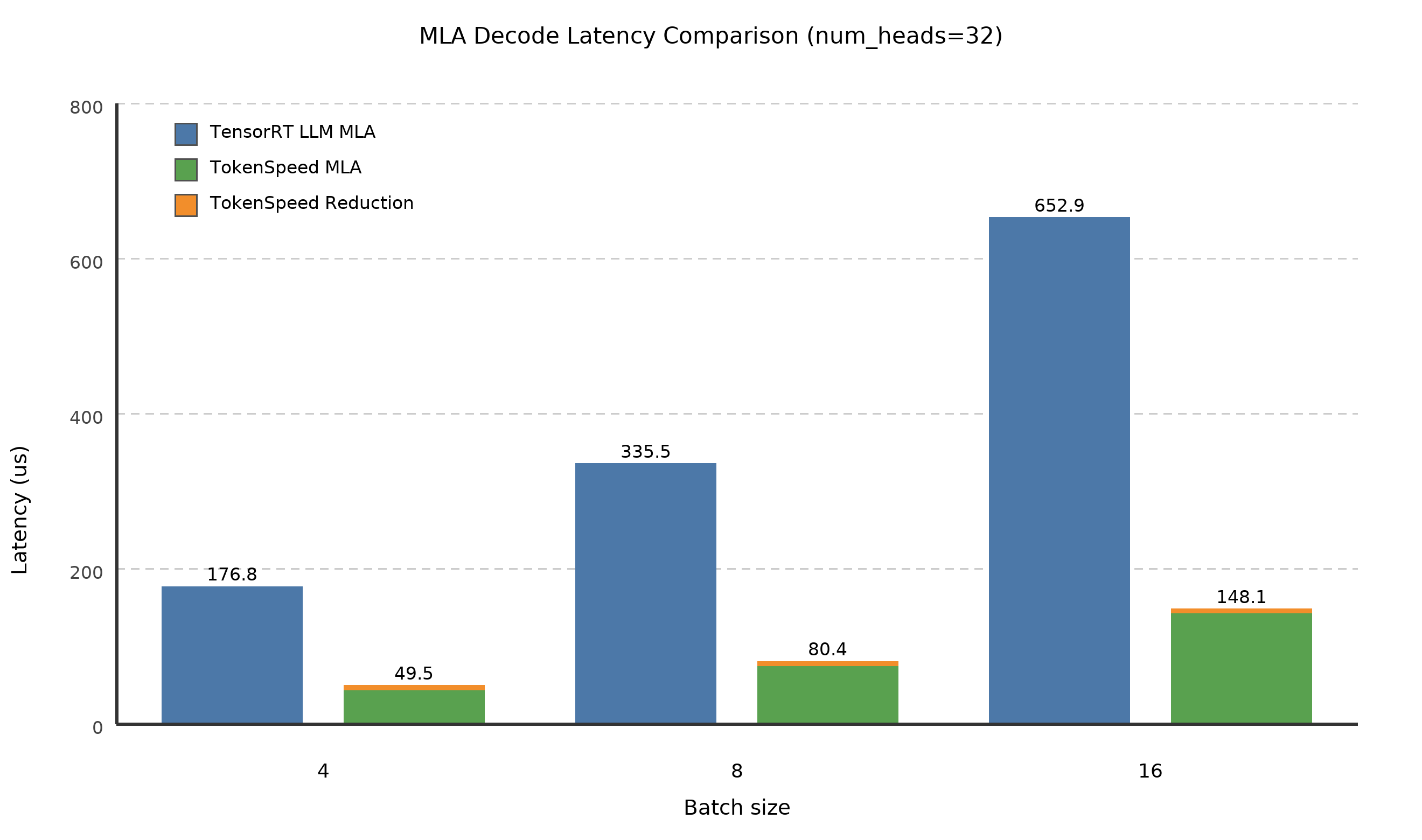
In the above test cases, q_seqlen = 4 and kv_seqlen = 80K.
TensorRT-LLM uses a single kernel for MLA decode, which appears to adopt a swap-AB strategy in the tested cases. In contrast, TokenSpeed’s MLA decode kernel uses a two-kernel implementation: one kernel computes the MLA decode with split-KV, and a second kernel performs the reduction of the split-KV partial results.
Key Optimization of TokenSpeed MLA decode kernel: Group q_seqlen and num_heads into BMM1 M
In mla_decode.py, mla_decode_fp16.py, and mla_decode_fp8.py, decode uses
fold_sq_factor to partially fold query tokens into the head axis when
num_heads < 128. q_seqlen can be any positive length; the runtime chooses
the largest factor F such that: q_seqlen % F == 0 and
num_heads * F <= 128. If no factor greater than one divides q_seqlen, the
kernel does not fold and schedules the full query sequence dimension directly.
The folded execution shape becomes:
H_eff = num_heads * Fq_seqlen_eff = q_seqlen / F
This improves BMM1 M-dimension utilization and reduces tile waste in small-head
decode scenarios, especially token-by-token agent traffic. Example:
num_heads=64, q_seqlen=4 chooses F=2, so two query tokens are folded into
M (H_eff=128) and the remaining two query groups are scheduled on the
scheduler second dimension (q_seqlen_eff=2).
Other optimizations include:
- Using 2CTA UTCMMA instruction to reduce shared memory usage.
- Try to use as less mbarrier as possible.
- Split kv loading warp to get more latency hiding ability. After loading K, V is already in the L2 cache. Loading K of next tile will not have to wait for the completion of V loading.
- Using multiple stage (sub-tiling) for STG in epilogue.
The performance numbers can be collected using the following command line:
python ./tokenspeed-mla/python/tokenspeed_mla/mla_decode_fp8.py \
--batch_size 4 \
--softmax_scale 0.07216882 \
--page_size 64 \
--seq_len_k 81920 \
--in_dtype Float8E4M3FN \
--out_dtype Float8E4M3FN \
--seq_len_q 4 \
--warmup_iterations 1 \
--iterations 10 \
--num_heads 16 \
--skip_ref_check
Kernel Capability Summary
MLA Prefill (tokenspeed_mla_prefill)
What it supports:
- Ragged varlen prefill without padding:
Q: [sum(q_lens), h_q, d_qk]K: [sum(kv_lens), h_k, d_qk]V: [sum(kv_lens), h_k, d_v]
- Different Q/KV sequence packs (
cum_seq_lens_qandcum_seq_lens_kvcan differ) - Causal and non-causal execution
- Optional LSE return (
return_lse=True) - PDL enable/disable (
enable_pdl) - Kernel compile cache keyed by static config (
dtype,d_qk,d_v, causal, LSE, PDL, etc.) - Skip-correction is enabled in the wrapped FMHA path.
- ex2-emulation (disabled by default on B200, and not supported on B300)
- Two different MLA Prefill backends:
- CuTe DSL JIT backend (default)
- AOT binary backend (if compatible SO is present)
Input/output dtype behavior:
- CuTe DSL backend accepts input dtypes supported :
torch.float16,torch.bfloat16,torch.float8_e4m3fn,torch.float8_e5m2- MLA Prefill only support
torch.float8_e4m3fn
- Prefill output tensor is BF16 (
torch.bfloat16) - Optional LSE output is FP32
Backend selection:
- Default: CuTe DSL JIT (
TOKENSPEED_MLA_PREFILL_BACKEND=cutedsl) - Optional: binary AOT (
TOKENSPEED_MLA_PREFILL_BACKEND=binary) - Binary
.sopath override:TOKENSPEED_MLA_FMHA_BINARY_SO - Availability probe API:
has_binary_prefill()
MLA Decode (tokenspeed_mla_decode)
What it supports:
- Query shape:
[B, q_len, H, kv_lora_rank + qk_rope_head_dim] - KV cache shape:
- 3D:
[num_pages, page_size, D_total] - 4D accepted and normalized internally
- 3D:
- Auto
split_kv+ workspace sizing and caching - Supports FP16/BF16/FP8; FP8 path writes BF16 output.
- Supports
H <= 128and1 <= q_len <= 4; for example,H=64, q_len=4is supported. split_kvandworkspace_sizeare computed and cached from runtime shape/device info.is_var_seq,is_persistent, andenable_pdlaffect scheduling/compile variants.causal_maskis currently effective on the FP8 decode kernel path.- Optional
outtensor reuse is_var_seqandenable_pdlcontrols
Minimal Usage
1) Decode
import torch
from tokenspeed_mla import tokenspeed_mla_decode
# query: [B, q_len, H, D_qk]
# kv_cache: [num_pages, page_size, D_total]
out = tokenspeed_mla_decode(
query=query,
kv_cache=kv_cache,
workspace_buffer=workspace_buffer, # torch.int8, 1D
kv_lora_rank=kv_lora_rank,
qk_rope_head_dim=qk_rope_head_dim,
block_tables=block_tables, # [B, max_pages]
seq_lens=seq_lens, # [B]
max_seq_len=max_seq_len,
softmax_scale=softmax_scale,
enable_pdl=False,
)
2) Prefill
import torch
from tokenspeed_mla import tokenspeed_mla_prefill
# query: [sum(q_lens), h_q, d_qk]
# key: [sum(kv_lens), h_k, d_qk]
# value: [sum(kv_lens), h_k, d_v]
out, lse = tokenspeed_mla_prefill(
query=query,
key=key,
value=value,
seq_lens=seq_lens,
cum_seq_lens=cum_seq_lens_kv,
max_seq_len=max_kv_len,
batch_size=batch_size,
softmax_scale=softmax_scale,
is_causal=True,
return_lse=True,
cum_seq_lens_q=cum_seq_lens_q, # optional, when Q/KV lengths differ
max_seq_len_q=max_q_len, # optional
enable_pdl=False,
)